この論文では効率的な並列ソーティングがテーマになっている。 並列ソーティングでは、ソートした結果を各プロセッサーに配布する必要があるが、この配布の仕方には2種類存在する。
この論文では、-balanced partitonのアルゴリズムについて考える。
並列でのソーティングには以下の2種類の大きな種類がある
partition-based sorting algorithmsでは、元データを均等に分割するパーティションを決定し、そのパーティションに基づいてデータを再配布することによってソートを行う。 partition-based sorting algorithmsには、merge-basedに比べてコミュニケーションコストが低いため、現代のアーキテクチャに向いているという利点がある。 既存の最先端の並列ソーティングのアルゴリズムでは、samplingとhistogramingというテクニックが利用されている。 この論文では、samplingとiterative histogramingを組み合わせてpartitionを探索するHistogram sort with sampling(HSS)を提案している。 このアルゴリズムは、既存の最も良いアルゴリズムに対して、分の1のコミュニケーションコストでpartitionを発見することができる。
各プロセッサーは個のキーを持つ。
注意点
番目のプロセッサーはソート済みのシーケンスの番目のサブシーケンスを持つようにキーを再分配することがアルゴリズムのゴール
並列ソーティングでは、ソート後のキーの分布についてバランスが取れていることを求められるのが一般的である。 バランスについての制約には以下の2種類が存在する
locally balancedでは、各プロセッサーはより多くのキーを持たない。
globally balancedは、locally balancedよりも強い制約で以下の条件を各プロセッサーが満たす必要がある。
このときプロセッサーは、以上かつよりも小さいすべてのキーを持っていなければいけない。 この論文のアルゴリズムはglobally balanced distributionを達成する。 繰り返しアルゴリズムにおけるglobally balanced distributionの利点は、初期の分布がほぼソートされていてかつglobal balancedの場合、データの交換ステップのコミュニケーションが少ないこと
先行研究12で、どちらの分布のもとでもexact splittingが得られることは証明されている。しかし、locally balancedの場合は、自身が持っているデータすべてを1つか2つのプロセッサーと交換しなければならないプロセッサがー存在するかもしれないのに対して、globally balancedの場合は、各プロセッサーにおいて交換が必要なキーの数はたかだかとなる。よって、根本的な違いとしては、アルゴリズムの全実行時間においてload balanceが維持されているかになる。
この研究では、partition-based sorting algorithmにおけるdata-partitionステップに注力する。 partition-based sorting algorithmには以下が存在する
スタンダードなよく研究されていてる並列ソートアルゴリズム
各プロセッサーで個のkeyをサンプリングし、1つのプロセッサーにすべてのサンプルを集める。サンプルを集めたプロセッサーは、サンプルをから個のキーをsplitterとして選択する。
一般的にSample sortは下記の3つのフェーズで構成される
Sample sortで利用される2種類のsampling methodsについて取り上げる。
random samplingでは、各プロセッサーは自身が持つソート済みの入力を個のブロックに分割し、各ブロックから1つランダムにキーを選択する。はoversampling ratioと呼ばれる。 splitterは集めたサンプルを均等に分割するように選択される。 先行研究で以下の定理が示されている
Theorem 3.1
With samples overall, sample sort with random sampling achives load balance w.h.p..
regular samplingでは、各プロセッサーは自身が持つソート済みの入力を均等に分割する個のキーを計算し、サンプルとする。そのサンプルを1つのプロセッサーに集め再度splitterを計算する。これについても先行研究1,2が存在し、以下の定理が示されている
Theorem 3.2 If is the oversampling ratio, then sample sort with regular sampling achieves load balance.
samplingサイズの大きさから、regular samplingではsampling phaseはスケールしない。random samplingはより効率的だが、それでもload-balanced splittingを達成するためには大きなサンプルサイズが必要になるため、こちらもスケーラビリティは低い。
histogram sortは、splittersを決定するために大きなサイズのサンプルを利用するのではなく、splitterが存在するキーの区間を管理する。アルゴリズムの実行を繰り返すことで、この区間の範囲を狭めていき、全splitterの区間が所定の閾値よりも小さくなったら、splitterを確定する。データの交換フェーズはsample sortと同じ。
histogram sortの流れ
probeの改良は、ヒストグラムで隣接する区間を分割することで行われる。 Histogram sortは、任意のレベルのload balanceを実現することができ、各ラウンド使用するヒストグラムのサイズは程度となっており比較的小さいため、スケールさせることができる。しかし、ラウンド数は大きくなる可能性があり、特にデータの分布に偏りがある場合に顕著になる。を入力の範囲とすると、ラウンド数はたかだかとなる。Histogram sortは実際に超並列の科学アプリケーションで利用されている。例 ChaNGa
先行研究
(1)[https://ieeexplore.ieee.org/document/4134268]
(2)[https://ieeexplore.ieee.org/document/5470406]
HykSortは直近で最も優れた実践的なアルゴリズム。 HykSortはsample sortとhypercube quick sortのハイブリッドになっている。しかし、HykSortがsplitterの決定に使っているsamplingとhistogrammingの手法はHSSとは異なっている。HykSortはHSSと比較してワーストケースで少なくとも倍のサンプルが必要になる。実際にこの論文では、HSSとHykSortのsamplingをHSSのアルゴリズムに置き換えたものを実装して、収束が速いことを確認している。
AMS-sortはoverpartitioningをsamplingに使っているアルゴリズム。 AMS-sortがsplitterの決定に使っているscanning algorithmはhistogrammingを1ラウンドしかしなかった場合のHSSより優れている。 しかしhistogrammingを複数回繰り返すと、HSSのほうがより効率的になる。AMS-sortのscanning algorithmはマルチラウンドに拡張しづらいものになっている。また、AMS-sortはlocally-balancedしか達成しないがHSSはglobally-balancedを達成できる。
AMS-sortの流れ
アルゴリズムは高確率でlocally balancedなsplitterを決定することができ、oversampling parameterはrandom samplingのsample sortより小さい。
後ほど示す通り、histogrammingのコストは同じ数のkeyをsamplingするコストと漸近的に等しいため、AMS-sortは理論的にsample sortよりも優れている。
AMS-sortではヒストグラムを計算したあとにscanning techniqueを用いてsplitterを決定する。このアルゴリズムはヒストグラムをscanしていって、可能な限り最大のキーを順番にプロセッサーに割り当てていく。(実際にはヒストグラムのバケットを割り当てていく)これによって、各プロセッサーのロードがを超えないようにする。サンプルサイズが十分に大きければ、最初の個のプロセッサーの平均のロードは高い確率でより大きくなる。
locally balanced partitioningを達成するためにはサンプルサイズは必要になる。
HSSはsampling phaseとhistogramming phaseを交互に行う。これによって、sample sortに比べてサンプリングサイズを抑えることができる
最初に1ラウンドのhistogrammingを行うHSSについて考える。 この方式はAMS-sortよりも若干効率が悪くなっている。(倍になる) しかし、HSSは1ラウンドのhistogrammingをマルチラウンドに拡張することによって、globally balanced partitionを達成することができる。AMS-sortのscanning algorithmをマルチラウンドに拡張することは簡単ではない。 マルチラウンドのHSSはAMS-sortより効率的で、回のhistogrammingで漸近的な改善には十分となる。
HSSでは、各ターゲットレンジに含まれるsplitterの候補を見つけることが目的となる。 各について、にランクが含まれるキーが少なくとも1つサンプリングされれば、すべてのsplitterを決定することができる。直感的には、十分に大きなサンプルサイズであれば、このようなことが高確率で起こると考えられる。
Lemma 4.1
If every key is independently picked in the sample with probability, , where s, the oversampling ration is choesn to be , then at least one key is chosen with rank in for each , w.h.p..
証明の方針
について、1つもキーがサンプリングされない確率を上から抑える
splitterは個あるので、キーがサンプリングされないが存在する確率は
Lemma 4.1からTheorem 4.2を導出できる。 このTheoremはマルチラウンドのHSSの解析にも利用できる。
Theorem 4.2
With one round of histogramming and sample size , HSS achives load balance w.h.p..
ここからはHSSはラウンドを複数にすることでより効率的になることを示す。
HSSのsampling phaseでは、サンプルを入力のサブセットから選択する。初期状態ではは入力全体となる。ラウンドが進むごとには小さくなっていく。
HSSでのサンプリングでは、確率での各キーが独立にサンプリングされる。(これによって解析が簡単になる。) はsampling ratioと呼ぶ。これまで出てきたoversampling ratioとは異なる概念のため注意。サンプルサイズの期待値はとなる。(oversampling ratioの場合は、バケットごとにサンプリングされる)
アルゴリズムの流れ
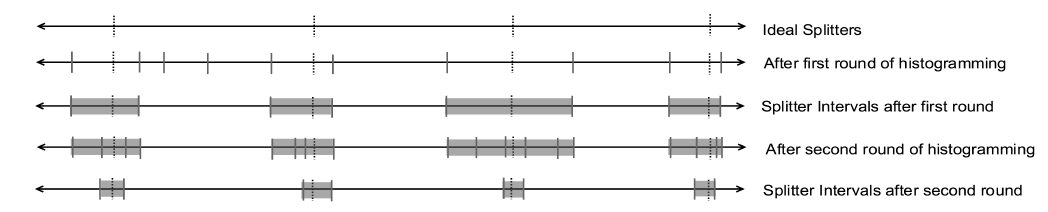
HykSortのサンプリングとHSSのサンプリングの違いは、HykSortはすべてのsplitter intervalから均等にサンプルするのに対して、HSSはintervalの長さに比例してサンプリングすること。これによって、HSSはintervalの縮小が速い。
アルゴリズムの進展によってsplitter intervalは縮小していくので、サンプリングの対象は毎回小さくなっていく。 をラウンド後にいずれかのsplitter intervalに含まれるキーの集合とする。すると以下のようにサイズを上から抑えることができる
不等式なのは重複があるから。 しかし、splitter intervalの選び方から、部分的な重複はなく、重複がないか一致しているかのどちらかしかない。
HSSの性能の証明の流れ
Lemma 4.3
if be the sampling ratio for the round, then at least one key is chosen from each after rounds w.h.p..
これが証明の流れの1にあたる補題
これはLemma 4.1をとして適用すれば即座に求まる。
Lemma 4.4
Let be the sampling ratio for the round, be the splitter interval for the splitter after rounds and denote the set of input keys that lie in one of the 's, then .
証明の流れの2のための準備1
この補題は、とが毎ラウンド改善されていくことを利用して、とを上から抑えることで証明される。は、ラウンド目のsplitter intervalの上半分。上半分と下半分を上から抑えることで全体のサイズを上から抑える。
Lemma4.5
If , then w.h.p..
証明の流れの2のための準備2
Lemma 4.4では期待値だったが、この補題で高確率でのサイズが小さいことを示す。
この補題の証明では、新しくとを定義する。
これによって、2つのsplitter intervalで重複していた部分を分割し、個別に扱えるようにする。(|は変わらないことに注意)
これを使って
を示す。(側も同じ手順で示す)
よって
w.h.p.
が証明できる。
Lemma 4.6
Let be the sample size for the round and , then w.h.p..
証明の流れの2にあたる補題
この証明によって、各ラウンドのサンプルサイズを上から抑え、またsampling ratioの比にしたがってサンプルサイズが減少していくことを示せる。
この補題の証明は以下の事実とチェルノフバウンドを利用する。
必要な補題は揃ったので、ここからはアルゴリズムが所望のload balancingを達成して停止させるために、どのようにsampling ratioを設定すればよいかを考える。
ラウンドのHSSで、ラウンドのsampling ratioを以下のように設定する。
すると、Lemma 4.3より、ラウンド目で全splitterは高確率で求まる。
Lemma 4.3
if be the sampling ratio for the round, then at least one key is chosen from each after k rounds w.h.p..
Lemma 4.5より、は、より小さい。
Lemma4.5
If , then w.h.p..
さらに、Lemma 4.6より、ラウンドでのサンプルサイズは高々
Lemma 4.6
Let be the sample size for the round and , then w.h.p..
よってTheorem 4.7が成り立つ
Theorem 4.7
With rounds of histogramming and a sample size of per round, HSS achives load balance w.h.p.. for large enough .
Theorem 4.7より、サンプルサイズとラウンド数にはトレードオフがあることがわかる。全ラウンドを通してのサンプルサイズを最小化するには、をに関して微分し、0をセットする。
これによって、Theorem 4.8が成り立つ
Theorem 4.8
With rounds of histogramming and samples per round ( from each processor), HSS achives load balance w.h.p.. for large enough p.
にするとexact splittingを得られる。
Threorem 4.9
HSS with samples per round overall cant achive exact splliting in rounds.
この論文では、並列計算のモデルにBSPを利用する。 BSPのアルゴリズムはsuperstepで構成される。 1つのsuperstepの中で、各プロセッサーは自身が持つデータを使ってローカルに計算を行い、データを送受信することができる。 superstepは同期のタイミングとなっている。
BSPのアルゴリズムの複雑性は以下の3つの要素から成り立っている
この研究では、プロセッサーは各superstepにおいて個のメッセージを送受信できるとする。 このモデル上で、Histogramming roundが増えるとsuperstep数は増えるが、コミュニケーションコストは低くなることを示す。
実行時間の解析では、sample sortとHSSを比較する。 この2つのアルゴリズムでは以下のコストは共通している。
データ交換後のマージのコストは
サイズのサンプルを1つのプロセッサーに集めるとすると、のコミュニケーションコストのsuperstepが必要になる。 送信前に各プロセッサーでサンプルがソートされていれば、マージステップの計算量はになる。
ローカルヒストグラムの計算量
グローバルヒストグラムはのコミュニケーションコストと計算量を持つ2回のsuperstepで計算できる
probeがヒストグラムの作成のためにブロードキャストされる。長さがのメッセージの送信のコミュニケーションコストは。 よって、サンプリングフェーズのコミュニケーションコストと計算コストはともにサンプルサイズに比例する。
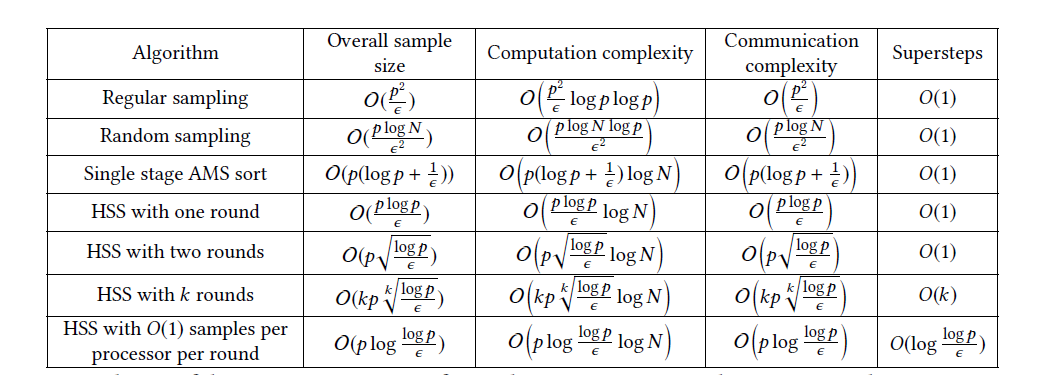
ベストな設定のHSSは他のアルゴリズムよりも複雑度の面で勝っている。
メモ
この論文はSPAA 2023のこの論文の前提となっている論文
2023の論文では解析をよりタイトにし、かつ、このアプローチのサンプルサイズとラウンド複雑性が最適であることを証明した。