論文のテーマ
この論文ではLocation-sensitive problemと呼ばれるタイプの問題をMPCで効率的に解くことをテーマにしている。
Location-sensitive problemの例
- String Matching
- Longest Palindrome Substring (LPS)
- Longest Common Substring (LCS)
- Longest Common Prefix (LCP)
Location-sensitive problemの特徴
- 入力文字列中の連続した文字列から情報をコンパイルする必要がある
- 前の文字及び文字列の順序に依存する
Location-sensitive problemがMPCで難しい理由
- 入力文字列の部分文字列は各マシンのメモリに乗り切らない場合がある
- 文字列を比較する場合ナイーブに実装すると非常に多くのラウンドが必要になる
この論文では、LPSとLCSをLCQクエリを効率的に解くことができるデータ構造LCPQ oracleを使って解くアルゴリズムを提案する。
また、LCPQ oracleを用いたsuffix arrayとsuffix treeの構築アルゴリズムも考案した。
さらに、Adaptive Massively Parallel Computation(AMPC)モデルにおいて、完全なsuffix treeを構築する手法についても提案した。
先行研究
これまでLocally Checkable Labelingと呼ばれるグラフの問題はMPCでよく研究されてきた。
Locally Checkable Labelingの例
- vertex coloring
- edge coloring
- maximal independent set
- maximal matching
先行研究のリンク乗せる
文字列に関する研究もよくされていて、この論文に関連がある問題としてはString Matchingがある。
Hajiaghayiらの先行研究によってString MatchingとInteger ConvlutionをO(1)ラウンドで解くアルゴリズムが提案されていて、これによってwildcardを含むString Matchingを効率的に解くアルゴリズムも提案されている。
上記の論文で使われているテクニックは、この論文でも利用している。
PRAMでもこれらの問題についてよく研究されている。
関係が深い論文
- Apostolicoらの論文
- LPSをO(n2)のトータルメモリで解く
- この論文で使われているアイディアは本研究でも利用している
- Iliopoulosらの論文
- suffix arrayをO^(n)のトータルメモリとO(logn)ラウンドで構築する
- この論文のテクニックは本研究のsuffix tree algorithmで利用している
他にもlongest common subsequenceについての研究や、バイナリ文字列のsufix treeの構築に関する研究がある。
モデル定義
モデルはMPCとAMPCを利用する。
MPC
- サイズO(n)の入力がマシンに分配される
- 各マシンはO(n1−ϵ)のメモリを持つ
- 各ラウンドでマシンは任意の計算を行い、ラウンドの最後に相互に通信する
この研究では0<ϵ≤0.5と仮定している。
AMPC
Adaptive MPCと呼ばれるモデル。
基本的にはMPCと同じモデルだが、各マシンはサイズO(n)のshared memoryが利用できることが特徴。
このshared memoryに書き込まれたデータをマシンは必要なときに読み出せる。
問題定義
記号の定義
- Σ
- 長さnの文字列s∈Σn
- s=s0s1,…,sn−1
- s[l:r)
- インデックスlからインデックスr−1までのsの部分文字列
- 特にs[l:n)のときsuffixと呼ぶ
- 同様にs[0:r)はprefixと呼ぶ
Longest common prefix queryとは
- 古典的な文字列の問題を解くために使われる原始的なツール
- 長さnの2つの文字列s,s′に対してLCPs,s′(i,j)は2つのsuffix$s[i;n), s'[j:n)$の共通のprefixの長さ
シーケンシャルな設定では二分探索とsuffixのハッシュ値の比較でO(logn)で解くことができる。
もしくは、s#s′のsufix treeがあればs[i:n)#s′とs′[j:n)のlowest common ancestorを求めることで解くことができる。
longest common substring(LCS)とは
- 2つの長さnの文字列s,s′が与えられたとき、共通する最も長い部分文字列を求める問題
longest palindrome substring(LPS)とは
- 入力文字列sに含まれる最も長い回文を求める問題
- sˉをsを反転させたものとすると、回文とはs=sˉとなる文字列
suffix treeとは
- trie-likeなデータ構造
- 各辺は文字列でラベル付けされる
- 文字列sのsuffix treeはsのすべてのsuffixを含む
- 各ノードはsの部分文字列を表す
- あるノードの文字列は根からノードまでたどる辺の文字列を結合したもの
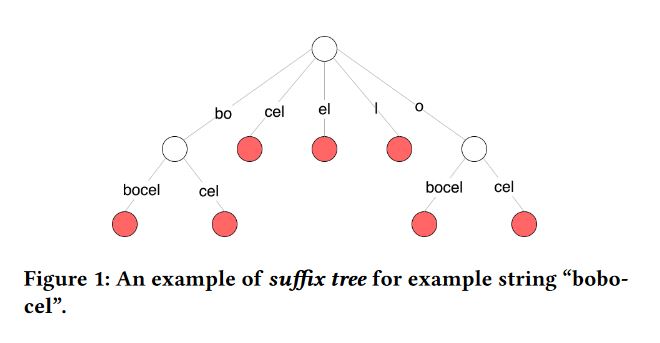
suffix treeはよく2つの文字列s,s′を特殊文字#で結合したs#s′に対して作られる。
suffix arrayとは
compressed suffix treeは複雑なので、suffix treeのかわりとして少し柔軟性を失ったかわりにシンプルなデータ構造として作られたのがsuffix array。
suffix arrayはsuffixをある順列に従ってソートしたもの。
結果
この研究では、location-sensitiveな文字列問題を解くための汎用的なフレームワークを提供する。
その核となるデータ構造がLCPQ oracleである。LCPQ oracleは多くのlongest common prefixクエリを同時に処理することができるデータ構造となっている。
多くのlocation-sensitiveな文字列問題は多項式数のLCPクエリに変換できるため、LCPQ oracleを利用することで多くの問題を効率的に解くことができる。
LCPQ Oracle
2つの文字列sとs′が与えられたとき、LCP query q=(i,j)はs[i;n)とs[j:n)のLCPを返す。
LCPの計算における問題点
- suffixの長さは最大でO(n)になる
- 1つのマシンのローカルメモリはO(n1−ϵ)であるため、単純には比較できない
- ナイーブに長いsuffixのLCPを計算しようとするとO(nϵ)ラウンドが必要になる
これを解決するために以下を利用する
- Block-based Data structures
- hash
- Modular Partitioning
イメージとしては、LCPQ oracleは以下のようなデータ構造になっている。
- 入力文字列をブロックと呼ばれるサイズnϵの部分文字列で管理
- 各iについてs[i,i+nϵ],s[i+nϵ,i+2nϵ]のようにハッシュ値を計算し、1つのマシンに集める
クエリの処理は以下の順序で行う
- LCPをラフに推測するためにs[i:n)とs[j:n)のブロックを1つのマシンに集める
- ハッシュ値が一致しなくなるブロックを探す
- そのようなブロックが見つかったら、オリジナルの文字列を持つマシンに対してクエリを送り正確な解を計算する
ブロック数はO(n1−ϵ)個存在するため、3のステップを1つのマシンで行う場合はO(n2ϵ)個のマシンを用意し、それぞれにユニークなブロックのペアをもたせる必要がある。
このようなデータ構造であるLCPQ oracleはk=O(n1+ϵ)個の任意のLCPクエリQ={q1,q2,…,qk}にO(1)ラウンドで答える事ができる。
LCPQ oracleの構築にはハッシュを利用するため、この研究のアルゴリズムはすべて非決定的である。
また、この研究のアルゴリズムでは、O(logn)個の大きな素数を剰余の計算に利用する必要がある。
このコミュニケーションラウンドを避けるために、この研究ではマシンのメモリ制約にO(logn)を追加する。
また、各マシンはnϵ個のハッシュ値を保存する必要があるので、0<ϵ≤0.5という制約も追加する必要がある。
Lemma 3.1
For ϵ∈(0,0.5], there is an O(1)-round MPC algorithm, with O~(n1+ϵ) total memory and O~(n1−ϵ) memory per machine, which initializes the Longest Common Prefix Query(LCPQ) Oracle in O(1) rounds w.h.p., and then computes a collection of k=O(n1+ϵ) queries, Q={q1,q2,…,qk}, in O(1) rounds.
これまで説明しててきた基本的なLCPQ oracleから発展させてcompressed LCPQ oracleというものも提案している。
Theorem 3.2
For ϵ∈(0,0.5], there is an O(1)-round MPC algorithm with O~(n1−ϵ) memory per machine which initializes an LCPQ oracle in O(1) rounds w.h.p., and then processes a collection of k queries, Q={q1,q2,…,qk}, O(1) rounds. The total memory used by this algorithm is O~(n+k+min(n,k)⋅nϵ).
LPSとLCS
LPSとLCSはLCQ queryを使って解くことができる。
Theorem 3.3
For ϵ∈(0,0.5], there is an O(1)-round MPC algorithm that solves Longest Palindrome SubString(LPS) with O~(n) total memory and O~(n1−ϵ) memory per processor, w.h.p.
Theorem 3.4
For ϵ∈(0,0.5], there is an O(1)-round MPC algorithm that solves Longest Common Substring(LCS) with O~(n1+ϵ) total memory and O~(n1−ϵ) memory per processor, w.h.p..
既存のテクニックを使ったアルゴリズムでは、LPSとLCSともにO(ϵ1)ラウンドが必要だったが、これがO(1)ラウンドに改善できている。
LPSについてはトータルメモリもO(n1+ϵ)からO~(n)に改善できている
Suffix Tree
LCPQ oracleはsuffix arrayの構築にも利用できる。suffix arrayをsuffix treeに変換することができるため、LCPQ oracleを用いてsuffix treeを構築することができる。このsuffix treeの構築は既存の手法とは異なりAMPCを利用するとラウンド数とトータルメモリを削減することができる。
Theorem 3.5
For ϵ∈(0,0.5], there is an O(1/ϵ)-round MPC algorithm for computing the suffix array of a given string s with O~(n1+ϵ) total memory and O~(n1−ϵ) memory per processor w.h.p..
Theorem 3.6
(Suffix Tree in AMPC). For ϵ∈(0,1], there is an O(1)-round AMPC algorithm for computing the suffix tree of a given string s with O~(n) total memory and O~(n1−ϵ) memory per processor with high probability.
ビルディングブロック
ここからこの研究のアルゴリズムで利用しているツールの説明に移る。
- Block-based Data Structures
- Modular Partitioning
- Weighted Load Balancing
また、ここでアルゴリズムで利用しているハッシュ関数についても定義しておく。
hash(s[l:r))=(Σi=lr−1si⋅∣Σ∣r−1−i)modp
pは十分に大きな素数
Block-based Data Structures
Block-based data structuresでは、入力文字列sはサイズO(n1−ϵ)のnϵ個の連続するブロックに分割される。(おそらくアルゴリズムによってというよりは、初期の入力として分割して与えられる。)
記号の定義
- ブロック
- b0,b1,…,bnϵ−1
- マシン
- ブロックbαを持つマシンをμαとする
問題に2つ目の入力文字列s′がある場合は、ブロックとマシンをそれぞれbβ′,μβ′と表記する。
入力文字列のサイズが異なる場合は、sとs′に含まれない特殊な文字列で調整する。
あるマシンμαは以下のブロックを持つとする
- bα−1
- bα
- bα+1
すなわち、自分のブロックの前後のブロックにもアクセスすることができる。
Definition 4.1
(Block bα and Block Machine μα). There is a collection of nϵ machines {μ0,μ1,…,μnϵ−1} refered to as block machine for string s (and {μ0′,μ1′,…,μnϵ−1′} for string s′), where μα (and μβ′) contains the substring of the α-th block of s (and the β-th block s′) denoted by bα=s[αn1−ϵ:(α+1)n1−ϵ).
このデータ構造は以下のように利用される。
- ある関数fをすべてのブロックに適用する
- fで抽出した情報を1つのマシンに集める
- ϵ≤0.5なのでこれが可能
fには以下のようなマージ関数gが存在する必要がある。
- f(s)=g(f(s[0:i]),f(s[i:n]),i,n)
また、各マシンは自身のブロックについてセグメント木を構成し、f(bα[l:r])を高速に計算できるようにしておく。
これによって、O(n)個のf(s[l:r])クエリを2ラウンドで計算することができる。
Modular Partitioning
長さnの配列のModular Partitioningは、配列の要素をnϵの剰余に分割すること。
Block-based data structuresで分配されたブロックbαの部分文字列のハッシュ値を計算する場合を例に考える。
- 各αnϵ≤i≤min{(α+1)nϵ,n}についてhash(s[i:i+nϵ])を計算する
- 各0≤x<nϵについてマシンλxを用意し、imodnϵ=xとなる部分文字列のハッシュを割り当てる
これによって、1つのマシンで任意のiから始まる部分文字列についての計算を行えるようになる。
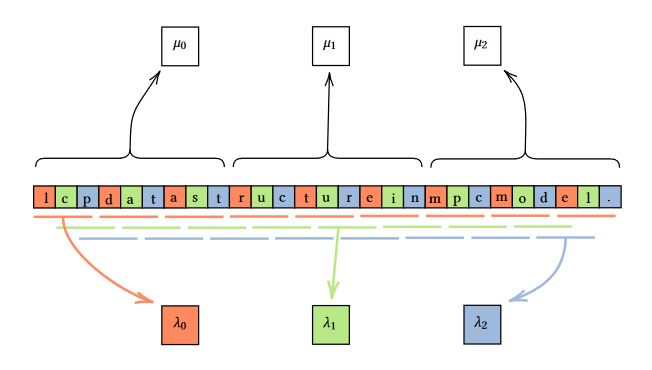
Definition 4.2
We denote a collection of nϵ mod machines {λ0,λ1,λnϵ−1} for string s (and {λ0′,λ1′,…,λnϵ−1′} for string s′), where λx (and λx′) contains the hash of substrings of length O(nϵ) starting at indices i so that imodnϵ=x.
Weighted Load Balancing
この研究のアルゴリズムでは多くのクエリを並列に処理する必要がある。
このクエリを適切にマシンに分配する必要がある。
Weighted load balancingはメモリ制約に違反しないように、データを割り当てられたクエリに比例して配布する2-roundアルゴリズムである。

論文情報
Location-Sensitive String Problems in MPC